I have been developing for the past 20 years, but I have never generated a self signed certificate until recently. Most of my development work is in house integration work. Little to no security has been required. Any applications I have developed have been deployed in house, and again no security has been required. Most tools I write run under Tomcat, but again, no security required. Everything ran under HTTP, not HTTPS. Getting stuff running under HTTPS seemed to be scary – simply because I never looked into it. Well, things change and I decided to give it a go.
In this first part, I’m going to go through how to generate a self signed certificate. These certificates are only really useful for development work, learning – or in house applications. For anything external facing, I recommend getting a proper certificate from an external provider.
Setting up OpenSSL
-
Firstly, you need to install openssl. For Windows, you can find a copy
here, or do a Google Search. For this tutorial though, I’ll be using linux on EC2 which already has open SSL already installed.
-
On Windows, there isn’t a openssl.cnf file, this needs to be created. Thankfully there are places on the internet where you can get one predefined.
But here is one I downloaded previously
openssl
-
On Windows again, we need to set the environment variable OPENSSL_CONF to the path to the openssl.cnf file.
For example :
SET OPENSSL_CONF=C:\temp\20190417\openssl.cnf
Generate the Certificate
| Note: There are a number of methods to generate certificates, but this is the one that I have used. |
openssl req -x509 -newkey rsa:4096 -keyout keyname.key -out certname.cer -days 365
Arguments:
req – certificate request and generation utility
-x509 – Outputs a self signed certificate instead of a certificate request.
-newkey <arg> – This creates a new certificate request and private key.
rsa:<nbits> – generates an RSA key of nbits size. In this case 4096 bit key.
-keyout <keyname.key> – specifies the filename for the key.
-out <certname.cer> – specifies the output filename for the certificate. If not specified, then the output is directed to standard output.
–days <numberOfDays> – specifies the number of days that the certificate is valid for. This is used with the -x509 option. If not specified, the default is 30 days.
When you run this, you will be asked a number of questions.
PEM pass phrase : Enter anything you consider consistent with the certificate. In my case, I entered “test”.
Verify PEM pass phrase : re-enter the pass phrase.
Country Name : 2 letter representation of your country.
State or Province Name : Enter as required.
Locality :
…
…
And so forth. Enter as best you can. Remember. this is for testing purposes, but for company certificates in use, I suggest you come up with a convention if one does not already exist.
An example call is:
[ec2-user]$ openssl req -x509 -newkey rsa:4096 -keyout mytestcert.key -out mytestcert.cer -days 365
Generating a 4096 bit RSA private key
...............................................................................................++
..................................++
writing new private key to 'mytestcert.key'
Enter PEM pass phrase:
Verifying - Enter PEM pass phrase:
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [XX]:AU
State or Province Name (full name) []:VICTORIA
Locality Name (eg, city) [Default City]:MELBOURNE
Organization Name (eg, company) [Default Company Ltd]:PERSONAL
Organizational Unit Name (eg, section) []:PERSONAL
Common Name (eg, your name or your server's hostname) []:mytestcert
Email Address []:admin@beanietech.com
[ec2-user@ip-172-31-25-116 certificates]$
This will generate 2 files. Your certificate (cer file) which is the public key you can pass on to people you want to exchange secure messages with, and the key file which you keep to yourself. This is used to decrypt messages.
Now, there are 2 types of certificate formats. PEM which is a base64 encoded text file. You can check these by looking at the cer file in a text editor. It might look like this:
-----BEGIN CERTIFICATE-----
MIIF/TCCA+WgAwIBAgIJAMXICEIvh11rMA0GCSqGSIb3DQEBCwUAMIGUMQswCQYD
VQQGEwJBVTERMA8GA1UECAwIVklDVE9SSUExEjAQBgNVBAcMCU1FTEJPVVJORTER
MA8GA1UECgwIUEVSU09OQUwxETAPBgNVBAsMCFBFUlNPTkFMMRMwEQYDVQQDDApt
eXRlc3RjZXJ0MSMwIQYJKoZIhvcNAQkBFhRhZG1pbkBiZWFuaWV0ZWNoLmNvbTAe
Fw0xOTA1MTMxMTM0NTVaFw0yMDA1MTIxMTM0NTVaMIGUMQswCQYDVQQGEwJBVTER
MA8GA1UECAwIVklDVE9SSUExEjAQBgNVBAcMCU1FTEJPVVJORTERMA8GA1UECgwI
UEVSU09OQUwxETAPBgNVBAsMCFBFUlNPTkFMMRMwEQYDVQQDDApteXRlc3RjZXJ0
MSMwIQYJKoZIhvcNAQkBFhRhZG1pbkBiZWFuaWV0ZWNoLmNvbTCCAiIwDQYJKoZI
hvcNAQEBBQADggIPADCCAgoCggIBAJkyuxteepbwlCiNV01YTR8xAx4dwSaEgeqk
n9OiPU6P72pySG4HbqpqIKpp228w4f7quODk5NKVRzOcCCB+1l74a3y1M2dCvwUH
xP6jgcy28qC/3OooasaiWuFPzG5tzr+z/ZpD0xm19CM0v/hMaZ5MH2/cQm4j2gjW
sGiQC1+HVLtIFMaKUgCpQPR1JeEOXpyDrg8Tzs8x/p8eq0WGdTHe9xLpOCqboptA
qbrRP45ThTJ5QhORGQE8XYxmF4xZQZHfe25fa+h+fzj/WYIqo/Sjx52y0657jvGl
The other type of file is a DER file format. This is a binary format for the certificate. If you look at one of these in a text editor, you will see strange characters.
What we have generated here is a PEM format certificate. PEM format certificates generally have the extension .cer, .pem or .crt.
DER certificates generally have the extension .der.
Viewing the Certificate
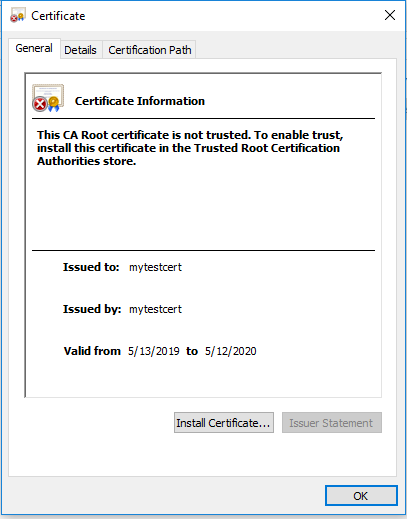
To view the certificate, you can just double click it in Windows. It will then give you the details of the certificate:
You can also use the following command to view the certificate:
openssl x509 -in certificateName.cer -text <-noout>
The Optional -noout (don’t include the angle brackets) does not display the certificate on the output.
With our sample certificate created, we get the following output:
[ec2-user@certificates]$ openssl x509 -in mytestcert.cer -text -noout
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
c5:c8:08:42:2f:87:5d:6b
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=AU, ST=VICTORIA, L=MELBOURNE, O=PERSONAL, OU=PERSONAL, CN=mytestcert/emailAddress=admin@beanietech.com
Validity
Not Before: May 13 11:34:55 2019 GMT
Not After : May 12 11:34:55 2020 GMT
Subject: C=AU, ST=VICTORIA, L=MELBOURNE, O=PERSONAL, OU=PERSONAL, CN=mytestcert/emailAddress=admin@beanietech.com
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (4096 bit)
Modulus:
00:99:32:bb:1b:5e:7a:96:f0:94:28:8d:57:4d:58:
4d:1f:31:03:1e:1d:c1:26:84:81:ea:a4:9f:d3:a2:
3d:4e:8f:ef:6a:72:48:6e:07:6e:aa:6a:20:aa:69:
db:6f:30:e1:fe:ea:b8:e0:e4:e4:d2:95:47:33:9c:
08:20:7e:d6:5e:f8:6b:7c:b5:33:67:42:bf:05:07:
c4:fe:a3:81:cc:b6:f2:a0:bf:dc:ea:28:6a:c6:a2:
5a:e1:4f:cc:6e:6d:ce:bf:b3:fd:9a:43:d3:19:b5:
f4:23:34:bf:f8:4c:69:9e:4c:1f:6f:dc:42:6e:23:
da:08:d6:b0:68:90:0b:5f:87:54:bb:48:14:c6:8a:
52:00:a9:40:f4:75:25:e1:0e:5e:9c:83:ae:0f:13:
ce:cf:31:fe:9f:1e:ab:45:86:75:31:de:f7:12:e9:
38:2a:9b:a2:9b:40:a9:ba:d1:3f:8e:53:85:32:79:
42:13:91:19:01:3c:5d:8c:66:17:8c:59:41:91:df:
7b:6e:5f:6b:e8:7e:7f:38:ff:59:82:2a:a3:f4:a3:
c7:9d:b2:d3:ae:7b:8e:f1:a5:6a:0f:6b:ec:20:fd:
f6:2c:8c:0f:25:c4:83:60:3b:4f:b2:52:72:04:50:
ea:3b:22:36:ee:53:79:72:e1:04:58:eb:91:79:dd:
bd:07:8d:29:7f:14:12:4c:78:66:de:d5:63:00:98:
52:b7:61:d7:7b:7f:75:55:40:1f:87:61:21:97:78:
9a:2f:e3:2a:fb:2f:0f:a3:50:14:b6:6d:56:7e:39:
27:94:d2:83:40:27:f6:d2:2e:57:0d:fc:94:54:3d:
ca:88:b3:75:b4:2f:97:fd:17:4a:8c:0c:78:66:42:
bf:c3:1a:7a:01:ba:3f:9a:fe:79:06:5d:ab:d9:f1:
da:1e:b3:6d:22:99:bd:db:77:9a:8e:68:51:47:d3:
30:5c:74:29:69:d2:0c:af:3d:2c:27:69:d5:b1:73:
9f:7a:d2:8c:d6:6f:9e:1b:d1:52:26:99:9b:3a:7d:
3e:48:53:4d:43:50:70:fe:74:83:32:34:c9:e4:b5:
32:71:37:7c:d5:39:fb:4e:c5:fd:4e:4a:4d:f2:5e:
50:97:1d:81:9b:f1:0b:3a:b9:ec:d0:b9:b4:e1:1e:
28:b6:50:15:70:17:cb:54:36:15:c6:94:fc:46:c9:
6f:7b:7b:59:ab:4f:f1:48:3c:5d:ef:f7:71:18:28:
87:e1:fb:80:ee:89:a9:13:2a:70:c0:8f:d3:ef:01:
81:d8:27:01:a7:11:a1:52:c3:d6:75:0f:9c:bc:42:
cd:5e:2b:46:77:9e:33:d9:92:f7:14:77:e0:44:92:
77:59:2f
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Subject Key Identifier:
99:62:57:CF:A8:41:83:BF:2E:0E:D8:51:D5:98:13:EA:78:B7:75:8C
X509v3 Authority Key Identifier:
keyid:99:62:57:CF:A8:41:83:BF:2E:0E:D8:51:D5:98:13:EA:78:B7:75:8C
X509v3 Basic Constraints:
CA:TRUE
Signature Algorithm: sha256WithRSAEncryption
0d:e3:53:28:e5:e8:9f:2b:e6:31:66:34:91:c9:79:43:53:e2:
33:db:e6:09:77:5a:4e:5f:91:88:a1:25:a6:f1:d5:bf:59:29:
64:b8:42:ca:ef:ba:2b:a7:b0:12:da:19:08:ff:f3:b3:09:f5:
bc:3f:87:fe:05:e2:25:95:0d:8e:48:72:7c:6f:c5:22:2a:dd:
40:d2:d2:a0:03:10:a1:09:00:c5:c8:2c:61:ff:98:5a:45:0c:
54:b5:80:4d:68:23:b9:57:91:71:0d:6f:8f:bb:92:55:70:d8:
3c:48:fd:b2:bb:a9:26:ba:7c:23:90:7e:f5:27:e7:a6:a1:a6:
02:7d:61:0d:bd:d3:d3:55:04:a2:b9:95:67:ce:cf:38:f2:4d:
45:cf:38:7e:35:e5:bb:3d:39:c4:b6:5d:e2:0c:40:87:87:e9:
c4:b7:83:4e:ca:f6:c6:7b:c6:5d:b4:c3:66:ec:f3:71:d1:d9:
b8:79:45:11:12:97:6e:5c:8f:e0:7c:b3:7c:5c:9e:5a:c8:99:
fe:35:9e:35:d4:55:66:c4:9d:8b:2d:d9:d4:05:85:bf:14:31:
d0:9e:d2:a5:64:46:fd:20:67:8f:ab:2b:83:8f:34:a9:0c:14:
6f:06:be:8b:e7:e4:c7:c0:15:61:e4:37:ef:3e:06:ac:73:61:
bc:b1:73:7b:53:3e:1b:5b:00:16:74:aa:1c:98:78:4c:68:1a:
8b:92:74:6c:f7:dd:f1:52:ec:b6:46:29:56:d3:85:46:f7:fa:
37:cf:3a:f5:c4:61:f0:bd:ed:63:e8:63:70:59:40:c1:72:21:
f2:19:f1:55:e7:df:bb:30:0d:2f:8a:bf:80:ae:b3:9e:b8:5c:
4e:13:98:87:80:61:06:94:0f:e3:9d:f0:c4:9c:a9:1b:9d:34:
47:84:1c:05:bb:cf:f8:7f:6d:8e:b5:3b:44:34:77:29:2f:a7:
ef:4e:46:48:0c:53:b9:ec:bc:1c:ec:39:e4:46:30:19:10:d4:
80:03:92:d2:98:ff:e9:57:f4:8b:18:da:94:7b:f1:55:1e:4c:
e7:3e:ce:c8:94:bf:51:6d:5d:94:26:f4:7b:19:2e:98:4f:c6:
24:32:99:a7:28:51:a0:e4:43:7c:14:ac:63:44:ad:19:a3:18:
9f:97:a0:b9:d7:d3:49:09:7b:b9:fd:c3:cb:ed:dd:9f:f0:f3:
10:14:4a:7a:aa:3e:c7:dd:f6:2f:63:90:2f:f7:b2:07:47:c9:
fb:ab:e9:4c:c0:83:0e:00:69:58:e1:e8:c2:a5:09:5b:fb:3f:
d7:52:49:eb:0e:37:e5:0e:f3:4c:2b:00:c7:11:e3:ba:71:b7:
c2:7d:7d:b0:48:da:01:cc
Creating the pkcs12 file
The pkcs12 file is an archive format to store the private key with its x509 certificate. You can use the following command to create the pkcs12 file (with the .p12 extension). This file can be used for the keystore in Java applications such as Tomcat.
openssl pkcs12 -export -in certificateName.cer -inkey keyFilename.key -out p12Filename.p12
You will be asked for a phrase and a password. An example would be:
[ec2-user@ certificates]$ openssl pkcs12 -export -in mytestcert.cer -inkey mytestcert.key -out mytestcert.p12
Enter pass phrase for mytestcert.key:
Enter Export Password:
Verifying - Enter Export Password:
[ec2-user@ certificates]$ ls
mytestcert.cer mytestcert.key mytestcert.p12
[ec2-user@ certificates]$
Again, the password and passphrase is “test” for this example.
Creating A Keystore for Java (.jks)
Make sure you have java installed. You can now create a keystore for Java.
Use the following command to create the keystore:
keytool -importkeystore -srckeystore p12Filename.p12 -srcstoretype pkcs12 -destkeystore jksFilename.jks
So for example:
[ec2-user@ certificates]$ keytool -importkeystore -srckeystore mytestcert.p12 -srcstoretype pkcs12 -destkeystore mytestcert.jks
Importing keystore mytestcert.p12 to mytestcert.jks...
Enter destination keystore password:
Re-enter new password:
Enter source keystore password:
Entry for alias 1 successfully imported.
Import command completed: 1 entries successfully imported, 0 entries failed or cancelled
Warning:
The JKS keystore uses a proprietary format. It is recommended to migrate to PKCS12 which is an industry standard format using "keytool -importkeystore -srckeystore mytestcert.jks -destkeystore mytestcert.jks -deststoretype pkcs12".
[ec2-user@ certificates]$
Note, the keystore password needs to be 6 characters, our password of “test” will not fit, so I used “test123”.
Now, to view the keystores contents, you can use the following command:
keytool -list -v storepass <Password> -keystore jksFilename.jks
So for example:
[ec2-user@ certificates]$ keytool -list -v -storepass test123 -keystore mytestcert.jks
Keystore type: JKS
Keystore provider: SUN
Your keystore contains 1 entry
Alias name: 1
Creation date: Jul 8, 2019
Entry type: PrivateKeyEntry
Certificate chain length: 1
Certificate[1]:
Owner: EMAILADDRESS=admin@beanietech.com, CN=mytestcert, OU=PERSONAL, O=PERSONAL, L=MELBOURNE, ST=VICTORIA, C=AU
Issuer: EMAILADDRESS=admin@beanietech.com, CN=mytestcert, OU=PERSONAL, O=PERSONAL, L=MELBOURNE, ST=VICTORIA, C=AU
Serial number: c5c808422f875d6b
Valid from: Mon May 13 11:34:55 UTC 2019 until: Tue May 12 11:34:55 UTC 2020
Certificate fingerprints:
MD5: 35:AB:6C:B1:60:E7:AB:1E:09:12:80:CE:0C:E0:85:7B
SHA1: FA:3F:23:FF:3B:B3:1E:8A:1B:84:DB:E6:51:DD:75:0C:C5:62:AD:1E
SHA256: 26:22:D7:1D:83:07:11:A0:21:55:91:53:17:0E:6F:19:8F:34:06:37:83:E0:D3:36:6C:D7:69:C1:67:F9:E5:04
Signature algorithm name: SHA256withRSA
Subject Public Key Algorithm: 4096-bit RSA key
Version: 3
Extensions:
#1: ObjectId: 2.5.29.35 Criticality=false
AuthorityKeyIdentifier [
KeyIdentifier [
0000: 99 62 57 CF A8 41 83 BF 2E 0E D8 51 D5 98 13 EA .bW..A.....Q....
0010: 78 B7 75 8C x.u.
]
]
#2: ObjectId: 2.5.29.19 Criticality=false
BasicConstraints:[
CA:true
PathLen:2147483647
]
#3: ObjectId: 2.5.29.14 Criticality=false
SubjectKeyIdentifier [
KeyIdentifier [
0000: 99 62 57 CF A8 41 83 BF 2E 0E D8 51 D5 98 13 EA .bW..A.....Q....
0010: 78 B7 75 8C x.u.
]
]
*******************************************
*******************************************
Warning:
The JKS keystore uses a proprietary format. It is recommended to migrate to PKCS12 which is an industry standard format using "keytool -importkeystore -srckeystore mytestcert.jks -destkeystore mytestcert.jks -deststoretype pkcs12".
Securing Tomcat
Now that we have our certificate and our keystore (for testing purposes) we can now add the certificate to Apache Tomcat.
Place your jks file under your <tomcat home>/conf/SSL folder. This isn’t the standard directory, its just the directory that I like to use to place keystores and truststores in.
Then in the <tomcat home>/conf/server.xml file, find the following entry:
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
After this entry, add the following:
<!-- Added manually after the tomcat installation for SSL configuration -->
<Connector port="443" protocol="org.apache.coyote.http11.Http11NioProtocol"
clientAuth="false"
keyAlias="<Key Alias>"
sslProtocol="TLS"
keystoreFile="conf/SSL/keystoreFilename.jks"
keystorePass="<password>"
truststoreFile="conf/SSL/truststoreFilename.jsk"
truststorePass="<password>
maxThreads="150"
SSLEngine="on"
SSLEnabled="true"
SSLVerifyDepth="2"
/>
Where keyAlias is the alias of the certificate in the keystore. If you look above in the keystore contents, we see the line
Alias name: 1
This is where the value was taken from.
We haven’t created a truststore here, but the same concepts are used to store the truststore certificates.
My entry is the following :
<!-- Added manually after the tomcat installation for SSL configuration -->
<Connector port="443" protocol="org.apache.coyote.http11.Http11NioProtocol"
clientAuth="false"
keyAlias="1"
sslProtocol="TLS"
keystoreFile="conf/SSL/mytestcert.jks"
keystorePass="test123"
maxThreads="150"
SSLEngine="on"
SSLEnabled="true"
SSLVerifyDepth="2"
/>
Now, if you start up Tomcat, you should be able to access it via https.
For example, if Tomcat was installed on your local system, you may go to: https://localhost
Now, you will receive a warning that the site is not safe in your browser. This is because you are using a self signed certificate. Just accept the warnings and allow access. You should then be able to access Tomcat over https.