In my previous blog post, I talked about multitasking and how to handle it by using pull instead of push. In this post, I would like to expand on the concept to teams and my thoughts on how to optimize.
Now for this, I’m going to assume you are wanting to use Agile methods, but this could possibly work with a staggerd waterfall approach.
The Basics
In order to increase flow, you have to start at the basics.
Lets say you have 4 stages before your piece of work goes into prod.

Each piece of work goes through each stage.
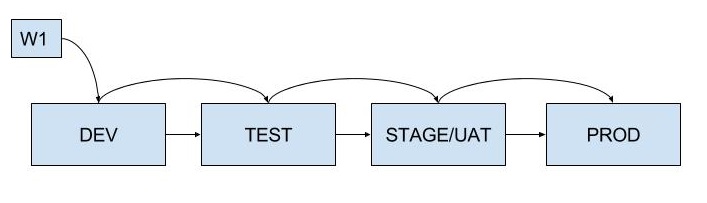
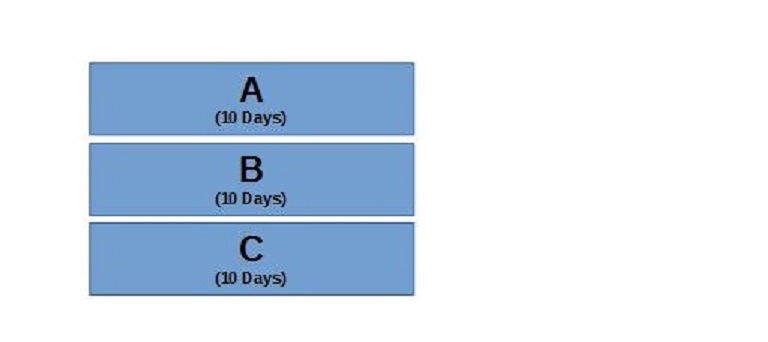
As you have multiple pieces of work, each piece will go through each stage as it is pulled through the system to completion.
Since I’m assuming that you are doing Agile, each piece of work should take no more then a couple of days to complete. So initially, Test should be waiting 2 days before it starts testing. Stage/UAT should be waiting 4 days and nothing should be going to prod until about day 6. Now I’m talking stages here – not people. This system works if you have one person doing all 4 stages or if you have separate people for each stage.
Again, this is highly speculative, things may vary from situation to situation but I’ll get to that later.
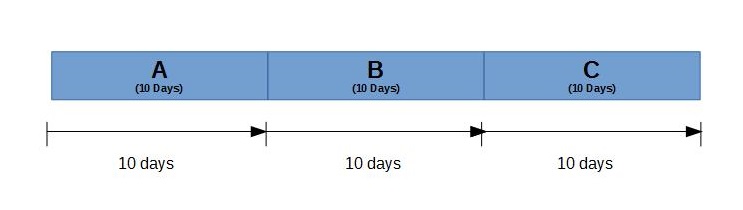
Now, does this model remind you of an an assembly line? If so, that is exactly what we are trying to model here. Once we have the assembly line running with features going and everyone is working on something, our next step is to try to achieve flow.
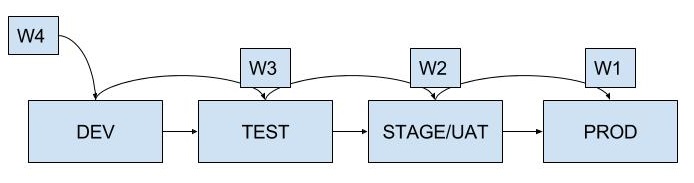
Flow
Flow just as the name implies is that the work flows from one stage to the next without stopping. Now I hear you say, that is impossible to achieve – well that is not the point. The point is to try to achieve that goal. If you don’t try, them you definitely will not reach that goal.
Now I hear you say, work doesn’t flow through evenly through. There are variances. One task may take 2 days. Another will take 5 days at the same stage. Another half a day. Also, Testing may only take a half a day for something that took 2 days to develop, or vice versa. I will go through that later, but I’m more interested in averages, but when there isn’t an average, the largest time will do.
Analyze The Variance
This is the next step. Analyzing the variances.
In order to do this, we need to identify the time it takes for a feature to travel within each stage, and how long it waits between stages.
The time it takes within each stage helps us identify bottlenecks.
Say for example we have the following times on average for each stage.
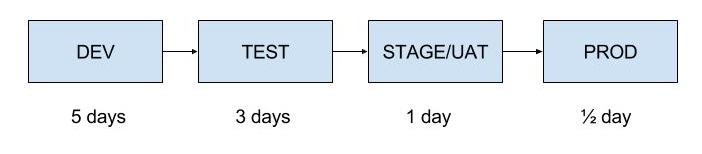
Here, the Testers are staved for work. The same with UAT and well, we’ll just say migration to prod is the same.
In traditional manufacturing, the way to control flow is to limit the work to the slowest point. In this instance it is development, which takes 5 days. Any project manager with half a brain will tell you this isn’t acceptable, and they are right. The throughput is too low. So how do you increase the throughput?
Increase Throughput
One way is to increase the number of developers.
Now for our example we have developers releasing a feature every 2 days.
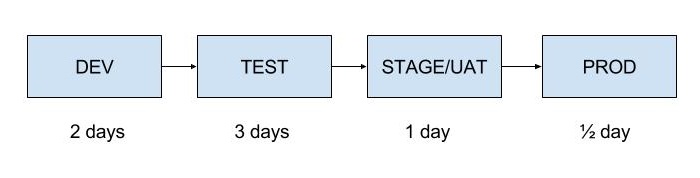
The Testers are now overworked. A backlog occurs before the testers and will keep occurring. This in itself is not a bad thing, but it needs to be managed. How can you do this, again, with Agile, cross functional teams, if the buffer for test gets too large then Developers can move across to the Testing stage and do testing. When the buffer drops down to a more manageable level, they can move back to Development.
What if increasing the number of developers isn’t an option but you still need to increase throughput. Another way to increase throughput is to identify tasks in the bottleneck stage and try to remove any non-value added work.
This in itself is a lot more difficult to do, but it is significantly cheaper. You have to really think what the developer is doing, determine if the step they are doing is really required or if the step can be done differently or more efficiently. It will take a lot of work, but ultimately it is cheaper for the simple reason you are not paying for another resource.
Now what I have said above isn’t new. Its been talked and implemented in the manufacturing world for at least the last 40 years and is known as part of the “The Theory Of Constraints”.
I know what you are thinking. It’s only a “Theory”. It’s just made up. Well, the person who came up with the “Theory” was Eliyahu M. Goldratt. A physicist, and in physics, a Theory is backed up by empirical evidence through many experiments. It is not something you just make up. It is only called a Theory because in physics as well in the sciences, there is always the possibility that the subject can be proven or disproved by a better process, equation or “Theory” that has been proven by empirical evidence. Goldratt applied the same principles to his “Theory of Constraints”.
In the book “The Goal”, Goldratt used an analogy of boy scouts walking along a track to describe this system and I’m going to steal the same analogy here.
Imagine a line of boy scouts walking down a track. Some boys are faster, and some are slower. The fast boys if they continue walking at their own pace will end up going so far ahead, that you can’t see them.
The boys that are too slow, end up falling behind and keep falling so far behind that you cannot see them either. So what is the solution. Goldratt used a proverbial rope to tie the boys together. The boys that go too fast get tugged back by the rope.
The boys that go at normal pace also get tugged by the rope. They all get tugged by the slowest person. There is no point pulling the last boy along as all you would be doing is dragging him along. Not a nice thought. So everyone walks at the slowest persons pace.
The only way you can get the whole troop to get faster is to increase the speed of the slowest person. The bottleneck. Goldratt called this “Drum, Buffer, Rope”.
Drum – The pace is set by the slowest person/process. ie, everyone follows the same rhythm of the drum.
Buffer – The slack in the rope. There needs to be some buffer to be able to handle outages and variances. Not too much buffer, nor too little. Experimentation will help determine the best level.
Finally, the rope. The rope implies a pull system. Work is pulled along the line rather than being pushed. As I mentioned in my previous post, this is how the Kanban system works. It makes sure that no person or process is overworked.
Goldratt had 5 steps to achieve this.
- Identify the bottleneck. I’ve described a couple of methods to do this above, but the only way you can identify a real bottleneck is through single piece flow.
- Exploit the bottleneck. What does this mean. Try to make the bottleneck faster by finding ways to quicken the work. Eliminate waste or try doing something differently to see if it does it quicker. Also make sure it is never staved of work.
- Subordinate the bottleneck. This is where you slow everything down to the bottleneck speed.
- Elevate the bottleneck. In this case, if you still need to increase throughput, add more resources.
- Finally, repeat the process fort the next bottleneck.
The steps are simple, but implementing them can be extremely difficult. Half the time you don’t know what you are doing, but this is where experimentation comes in. Keep trying new things, but remember Peter Palchinsky’s principle:
- Seek out and try new things.
- when doing something new, so it at a scale where failure is survivable, ie. not at the cost of your productivity or at a monetary cost so great that if it doesn’t work your company goes bankrupt etc.
- Finally, seek feedback and learn from your mistakes as you go along.
Waiting
Now, another thing I mentioned previously was recording the time between stages. In other-words, how long a piece of work waits before it is worked on.
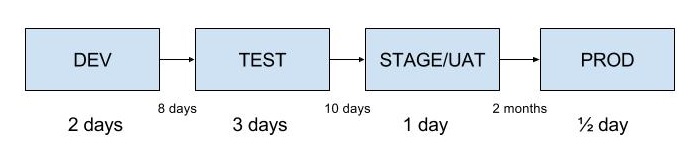
This diagram is a very rudimentary value stream map. A value stream map shows how long it takes for a piece of work from conception to fruition to start giving value. When does a piece of work start giving value in software? When it is being used in production.
Here we have the times a piece of work waits before it is processed by the next stage. Those of you in Agile probably don’t see times like these, but with Waterfall, you definitely do. In this made up example, for a single piece on average to get to production there is 78 days of waiting! with only 6 1/2 days of active work being performed on this piece.
That means that it takes 84 days in this instance before a piece of code is helping your company make money. The shorter we make that time, the sooner the business gets the value, but also the sooner we are able to find out any problems and address them.
Now normally I would end here, this article gives some of the building blocks to improve throughput and increase speed, but as these techniques are simple and for quite a number of people seem to make sense, I thought I would go through a trap that I’ve seen.
False Flow or Multitasking By Stealth
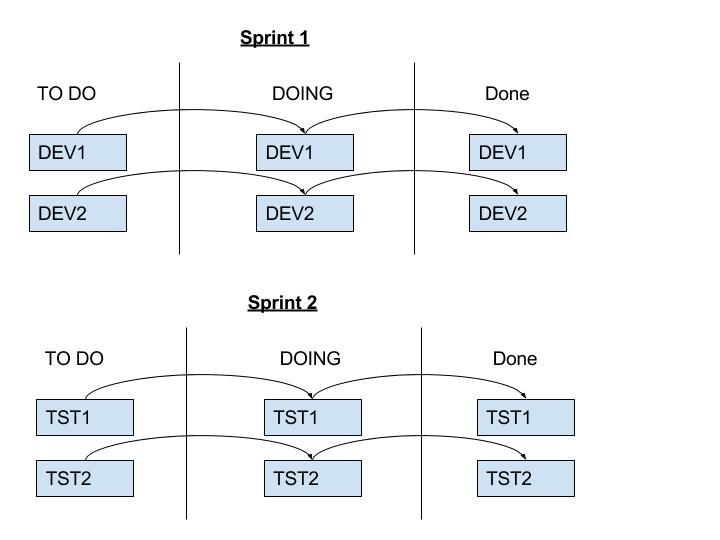
I’ve seen the following done with some variances, but doing something similar using a Kanban Board for a team starting out with Scrum.
Here you have a piece of work flowing through the Kanban board, but its not actually a piece of work, its a task. A development task. Here, development tasks are being batched up, but because there is one card per task – not per piece of work, there is no flow although the movement of cards gives the illusion of flow.
I’ve also made it quite obvious here by naming the tasks “DEV”, but this is not always the case.
The correct way to implement is to have the work all encompassing of all stages of the development cycle. The individual tasks for each stage linked to the piece of work. This highlights when you are doing proper flow as opposed to false flow.
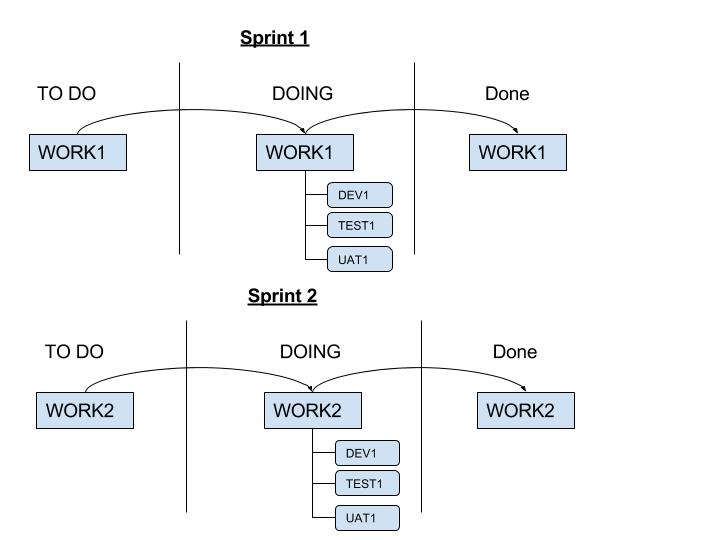
Using these techniques continuously over time, you should see improvements in throughput.
Please let me know your thoughts of this subject in the comments. Am I full of it or does this make sense. I’m very interested to know.